ABOUT THE COURSE :
Deep Learning has received a lot of attention over the past few years and has been employed successfully by companies like Google, Microsoft, IBM, Facebook, Twitter etc. to solve a wide range of problems in Computer Vision and Natural Language Processing. In this course we will learn about the building blocks used in these Deep Learning based solutions. Specifically, we will learn about feedforward neural networks, convolutional neural networks, recurrent neural networks and attention mechanisms. We will also look at various optimization algorithms such as Gradient Descent, Nesterov Accelerated Gradient Descent, Adam, AdaGrad and RMSProp which are used for training such deep neural networks. At the end of this course students would have knowledge of deep architectures used for solving various Vision and NLP tasks
Deep Learning has received a lot of attention over the past few years and has been employed successfully by companies like Google, Microsoft, IBM, Facebook, Twitter etc. to solve a wide range of problems in Computer Vision and Natural Language Processing. In this course we will learn about the building blocks used in these Deep Learning based solutions. Specifically, we will learn about feedforward neural networks, convolutional neural networks, recurrent neural networks and attention mechanisms. We will also look at various optimization algorithms such as Gradient Descent, Nesterov Accelerated Gradient Descent, Adam, AdaGrad and RMSProp which are used for training such deep neural networks. At the end of this course students would have knowledge of deep architectures used for solving various Vision and NLP tasks
INTENDED AUDIENCE: Any Interested Learners
PREREQUISITES: Working knowledge of Linear Algebra, Probability Theory. It would be beneficial if the participants have done a course on Machine Learning.
Nptel Deep Learning – IIT Ropar Week 2 Assignment Answer
Course layout
Week 1 : (Partial) History of Deep Learning, Deep Learning Success Stories, McCulloch Pitts Neuron, Thresholding Logic, Perceptrons, Perceptron Learning Algorithm
Week 2 : Multilayer Perceptrons (MLPs), Representation Power of MLPs, Sigmoid Neurons, Gradient Descent, Feedforward Neural Networks, Representation Power of Feedforward Neural Networks
Week 3 : FeedForward Neural Networks, Backpropagation
Week 4 : Gradient Descent (GD), Momentum Based GD, Nesterov Accelerated GD, Stochastic GD, AdaGrad, RMSProp, Adam, Eigenvalues and eigenvectors, Eigenvalue Decomposition, Basis
Week 5 : Principal Component Analysis and its interpretations, Singular Value Decomposition
Week 6 : Autoencoders and relation to PCA, Regularization in autoencoders, Denoising autoencoders, Sparse autoencoders, Contractive autoencoders
Week 7 : Regularization: Bias Variance Tradeoff, L2 regularization, Early stopping, Dataset augmentation, Parameter sharing and tying, Injecting noise at input, Ensemble methods, Dropout
Week 8 : Greedy Layerwise Pre-training, Better activation functions, Better weight initialization methods, Batch Normalization
Week 9 : Learning Vectorial Representations Of Words
Week 10: Convolutional Neural Networks, LeNet, AlexNet, ZF-Net, VGGNet, GoogLeNet, ResNet, Visualizing Convolutional Neural Networks, Guided Backpropagation, Deep Dream, Deep Art, Fooling Convolutional Neural Networks
Week 11: Recurrent Neural Networks, Backpropagation through time (BPTT), Vanishing and Exploding Gradients, Truncated BPTT, GRU, LSTMs
Week 12: Encoder Decoder Models, Attention Mechanism, Attention over images
Week 2 : Multilayer Perceptrons (MLPs), Representation Power of MLPs, Sigmoid Neurons, Gradient Descent, Feedforward Neural Networks, Representation Power of Feedforward Neural Networks
Week 3 : FeedForward Neural Networks, Backpropagation
Week 4 : Gradient Descent (GD), Momentum Based GD, Nesterov Accelerated GD, Stochastic GD, AdaGrad, RMSProp, Adam, Eigenvalues and eigenvectors, Eigenvalue Decomposition, Basis
Week 5 : Principal Component Analysis and its interpretations, Singular Value Decomposition
Week 6 : Autoencoders and relation to PCA, Regularization in autoencoders, Denoising autoencoders, Sparse autoencoders, Contractive autoencoders
Week 7 : Regularization: Bias Variance Tradeoff, L2 regularization, Early stopping, Dataset augmentation, Parameter sharing and tying, Injecting noise at input, Ensemble methods, Dropout
Week 8 : Greedy Layerwise Pre-training, Better activation functions, Better weight initialization methods, Batch Normalization
Week 9 : Learning Vectorial Representations Of Words
Week 10: Convolutional Neural Networks, LeNet, AlexNet, ZF-Net, VGGNet, GoogLeNet, ResNet, Visualizing Convolutional Neural Networks, Guided Backpropagation, Deep Dream, Deep Art, Fooling Convolutional Neural Networks
Week 11: Recurrent Neural Networks, Backpropagation through time (BPTT), Vanishing and Exploding Gradients, Truncated BPTT, GRU, LSTMs
Week 12: Encoder Decoder Models, Attention Mechanism, Attention over images
Nptel Deep Learning – IIT Ropar Week 2 Assignment Answer
Week 2 : Assignment 2
Due date: 2025-02-05, 23:59 IST.
Assignment not submitted
1 point
1 point
1 point
The diagram below shows three functions f,gf,g and hh The function hh is obtained by combining the functions ff and gg. Choose the right combination that generated hh.



1 point
Consider the data points as shown in the figure below,
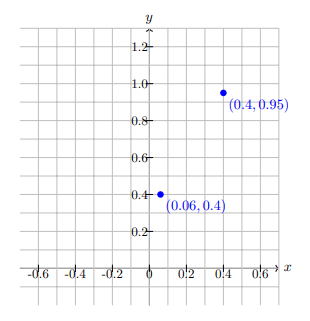
Suppose that the sigmoid function given below is used to fit these data points.
11+e−(20x+1)11+e−(20x+1)
Compute the Mean Square Error (MSE) loss L(w,b)L(w,b)
1 point
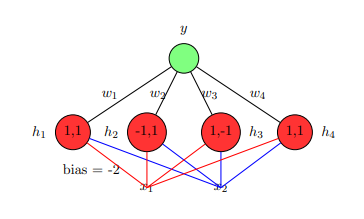
Suppose that we implement the XOR Boolean function using the network shown below. Consider the statement that “A hidden layer with two neurons is suffice to implement XOR”. The statement is
 w=−1w=−1 (red edge)
w=−1w=−1 (red edge)
 w=+1w=+1 (blue edge)
w=+1w=+1 (blue edge)